We deliver
Care-enhancing insights that help hospitals improve patient outcomes
Our software uses artificial intelligence and deep domain expertise to enhance the delivery of highly specialized clinical practices.


Making healthcare work better
We know that data and artificial intelligence will transform healthcare. But we also know that healthcare is built on human expertise and empathy. That’s why we believe in transforming healthcare using a clinician-focused approach.
Read our vision for the future of healthcare
Datlowe
Augmenting the expertise of healthcare specialists with artificial intelligence
Our software uses artificial intelligence and deep domain expertise to enhance the delivery of highly specialized clinical practices.
-
Built in collaboration with clinical experts
We develop products in close collaboration with clinical specialists, generating insights that enhance healthcare delivery within their specialism.
-
Building a full patient-centric view
We integrate data from existing EHR systems, providing clinicians with a comprehensive timeline of relevant patient interventions and risk factors.
-
Maximizing valuable clinician time
We perform up to 90% of the data collection and analysis work needed to guide clinical decision making, helping clinicians spend more time on treatment.
-
Improving patient care and outcomes
We enable healthcare professionals to be fully present with patients, helping to improve their quality of care and reduce the risks of follow-on complications.

Health-specific technology you can trust
We know that in extreme cases healthcare decisions can mean the difference between life and death. That’s why our product insights are built on transparent, highly specialised, and task specific clinical expertise that healthcare professionals can trust.
Learn how it worksOur products
Our products are built to fit
perfectly into the daily workflows
of clinical specialists
Automated surveillance of healthcare-associated infections
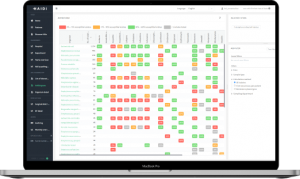
Automated patient risk assessment for clinical pharmacy
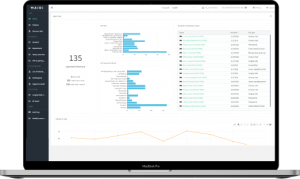

Datlowe references
Working in partnership
with great hospitals
30 +
18 000 +
Our philosophy
We believe that improving one life, by giving the right data to the right medical specialist at the right time, is worth more than a world of undeliverable hype about healthcare transformation.
Read more
Datlowe
Making healthcare work better for everyone
Medical specialist
Medical directors
Hospital management
IT management
